Engineering a Robust Community Platform: Overcoming Presence Data Challenges with pure Erlang
Delve into a journey of finding efficient data structure to a concrete live chat problem.
- Alexej Haak, Senior Engineering Manager at EFG
- Nelson Vides, Senior Consultant at Erlang Solutions

While building our Faceit Chat System, our primary challenge was to develop a scalable solution for managing presence status of users, which had become a bottleneck in our system’s performance.
Working closely on this project as the engineering manager, I had the opportunity to collaborate with Nelson Vides from Erlang Solutions to devise a solution and resolve this significant issue plaguing our chat experience.
In this blog post, Nelson will walk you through the journey of identifying the root causes, exploring potential solutions, and ultimately implementing a robust fix that has transformed our chat system’s reliability and efficiency.
Instant Messaging
Every time you send a message to your friend Joe, our servers need to find out if Joe is indeed online and route the message to his device. When you message your group of Counter-Strike friends, our servers need to find all members of the group at that moment, see who’s online, and forward the message to all online members. Most likely, you want to know who’s online to begin with.
The first problem is known as Messaging (sending of direct messages and publishing messages in groups) and Presence (the presence status of users). For that we take advantage of a good old protocol called XMPP, which stands for “eXtensible Messaging and Presences Protocol”. We use MongooseIM, a server written in the Erlang programming language by Erlang Solutions, of which I am one of its core developers. Erlang’s advantages lie in its ability to handle massive concurrency, fault tolerance, and distributed systems efficiently, making it ideal for building scalable, reliable, and maintainable applications, particularly in real-time communication and high-availability environments like our Chat System.
However, not all that glitters is gold, and in the realm of a functional and immutable programming language, performance is traditionally the challenge.
The challenge of very large presence sets
Granted, if you’re playing online competitive video games, we can assume you have a really good internet. But that doesn’t mean it is ok to send the player a 30MB payload at once of everyone that is online or offline when you enter a Counter-Strike tournament. You would never browse through such a massive list!
The challenge of managing presences for such a large community is two-fold. First we want to replace the initial load of presence data, which includes all users of the group, to just a paginated subset. Second, we want to be able to update such subsets by providing only deltas of changes. Note that, we also want to be able to manage such large data structures as fast as possible, since it is accessed by millions of players per month.
The presence list is ordered. First of all, the user wants to see who’s online. Then, within present peers, the user wants to order them by role (admins, generals, elite and the like). Finally throw alphabetical order and nicknames into the pot. We need a data structure capable of holding a very large ordered set.
It should be able to:
- Accept tons of mutations and reorderings: think of the people connecting and disconnecting.
- Report back indices of where things are being added and removed, in order to enable the deltas we need, in a very performant way, so that the updates are actually real-time.
And we have established our challenge.
In search of the right data structure
We follow Joe Armstrong’s, the creator of Erlang, adage:
Make it work, then make it beautiful, then if you really, really have to, make it fast. 90 percent of the time, if you make it beautiful, it will already be fast. So really, just make it beautiful!
We first make it work: just use a linked list! We design how the algorithm works, encapsulate the data structure into your usual `get`/`set` operations that return the index where the operation took place and design our network protocol. We write all the tests, and make them pass: classic Test-Driven Development (TDD) philosophy. We refactor, clean code, and ensure best practices like single responsibilities and encapsulation, finishing the TDD cycle and Joe’s “make it beautiful” concept.
It all just works, but one use-case which is happening hundreds of times per day on our system is players joining a new community. Adding just a hundred random new members to a big community takes around 1s. Obviously this takes way too long if you add to this all the other things happening to the system at the same time.
Measurements as part of the specification
I like to work under this adage of mine:
When it comes to performance, you only care about the code you have benchmarked!
Just like TDD gives you a safety net of functional tests for the future, I believe that the performance of your software is a specification of its functionality just like previous tests were. Therefore, it needs to be tested.
Just like fixing a bug, we first need to prove that the bug exists with a regression test. After your “fixed” bug does not reproduce anymore, your regression test stays to ensure the bug will not come back. With performance, you need to prove that the “bug” exists by introducing a test that measures the code. That will “prove” that your “fix” does indeed make the code faster, and it stays to ensure that the “bug” will not come back, that is, future changes won’t make the code slower.
So we measure. The runtime for these operations depend on the position in the set, as expected. Inserting into the top of the set is instant, but at the very bottom of a 250K list takes ~80ms. Deleting the last element takes just as much. Think of a few users going online and offline continuously and you build a stream of updates to the list where delays quickly accumulate and updates will fail to be real-time.
Now we found the bottleneck, it’s time to look for better data structures.
Looking into more performant alternatives
Erlang is a functional and immutable programming language. This means that inserting an element into the list will in reality recreate a new list, which, even with some optimisations about list reusing in place, means copying again and again enormous segments of memory. Immutability, while it plays in favour of concurrency, garbage collection, and reasoning about code, is often a liability when it comes to performance. Likely, we need mutations.
Native code
We consider resorting to a solution implemented in a classically native code, for example, C. Maybe skip all the memory safety risks of such a language and resort to Rust. Not wanting to reinvent the wheel, a Rust implementation of an indexed sorted set was readily available. A very good option and the fastest we were able to find. But it has its own disadvantages too. It introduces dependencies to new tooling to our building chain, that is, to Elixir and Rust compilers. Granted, these two languages are fantastic and well supported, but the tool introduces more unfortunate elements to our supply chain, like itself and a third-party tool gluing the BEAM and Rust runtimes.
Let’s have a measurement for reference, using the provided test suite: inserting a new element at any point in a set of 250K elements takes ~4μs.
I’m curious, can we give pure Erlang code a chance to compete against ~4μs?
Beyond Linked Lists
Inserting in a classic linked list means copying all the elements of the list up to the point of insertion. So, if we want to reduce the amount of elements being copied, what about having a list of lists instead? If you think about this data structure, it is actually a skip-list. We can extend the concept to nested lists, which effectively introduces more lanes into the skip list.
However, now we need to deal with issues of balancing the lanes, that is, when inserts will all fall into the same inner nested list, our lanes would be out of proportion, and operations can end up looking like operating over a flat linked list again. This not only looks tricky to implement, but it also rings a bell: it is the same issue binary trees face to keep their trees balanced.
Let’s do some reading.
Skip lists were introduced back in 1990, they are older than I am! A quick search of public skip list implementations in Erlang doesn’t return anything available that readily supports indexes, while the issue of rebalancing skip lists keeps ringing a bell: rebalancing binary trees. So, let’s look for already existing implementations of balanced binary trees in Erlang.
Balanced binary trees are part of Erlang’s standard library. The implementation is based on this research paper by Prof. Arne Andersson, from 1999, in turn based on this paper from 1993 by Andersson as well. In them Prof. Andersson argues, explicitly, in a comparison of his algorithm for balancing trees against the very skip list structure we started reasoning about. The code is much simpler and doesn’t currently support index operations, but its simplicity might make it easier to modify and add index support.
Bingo again: Order Statistic Trees
An Order-Statistic General Balanced Tree
Modifying the default implementation of sets (gb\_sets) to add support for indexes turned out to be no more
than a couple of hours. Add an extra couple of hours to introduce property-based testing for equivalence against the
previous flat-linked-list implementation, and we are ready to swap the underlying data structure.
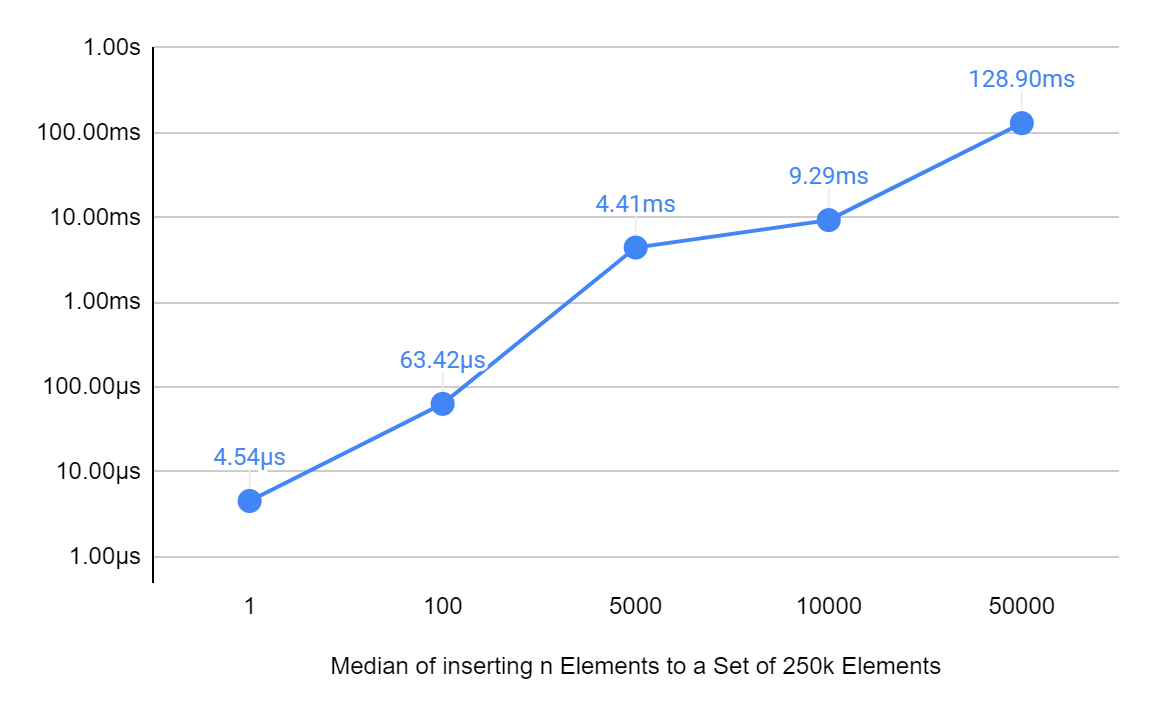
Run the same benchmark we already had written before, that is, inserting a new element at an arbitrary position to a set of 250K elements.
As you can see in this image, the median insert time is 4.5μs for 1 element!
That is fantastically competitive! Let’s try more combinations, what about adding an element at any point in the set? A few hours of benchmarks running against all positions in the list gives us 8μs on average, with the fastest cases at 3μs and the slowest at 17μs, in pure Erlang.
The algorithm has an amortised runtime of 1.46*log(n), and the logarithm base two of 250K is ~8, that is, on
average it will take 12 (exactly 11.68) steps to apply any operation. And including the most unfortunate operations
that required the entire 12 steps and some rebalancing, the worst case is still 17μs.
Seems like we have a fair competitor.
Final round of tests
Our main use case is covered, but how does our data structure perform in other situations? Let’s get some useful data about the most common operations in our nifty presence list.
When rolling out an upgrade that requires restarting the server, we need to create the data structure from scratch.
In this situation we need to rebuild the full presence list.
This is luckily just the case of inserting into an empty set, and should always be faster then our already established
128ms for inserting 50k elements into a set of 250k in the graph above!
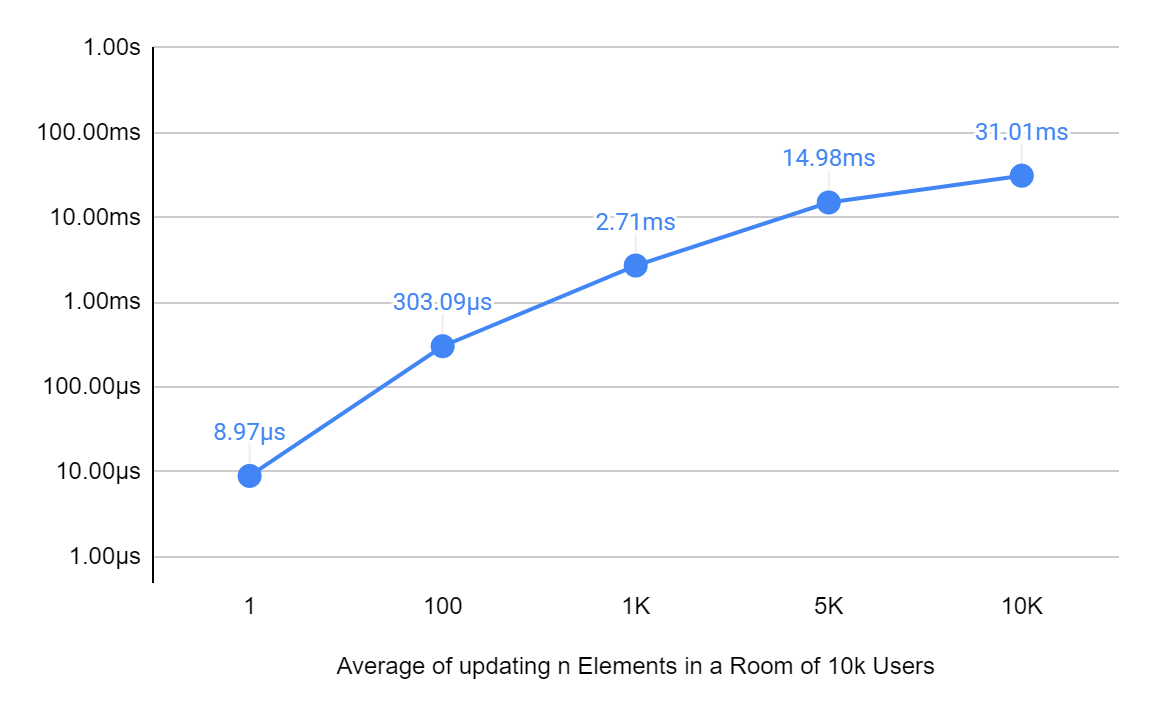
When people come online we need to change their position, because of the ordering of the list (in most cases we order first by online status, then by role, and then by name). Let’s test different amounts of people coming online for different set sizes:
Lastly, when a user checks the online status of other users in the room, we need to return a subset of the full presence list. Often, they will just check the first page, which is basically instantaneous!
Conclusion
To resolve our chat performance issue, we looked for a better data structure to hold the list of active users (presence). The solution combines nested skip-list and order statistic tree to efficiently track users’ presence in a chat room. The new solution outperforms our initial linked list solution by 20,000 folds for the most costly operation, like adding or removing an element from the bottom of the list.
I have shown that competitive solutions can be implemented in pure Erlang nowadays, which makes it memory-safe out of the box, and simplifies concurrency. This enables us to easily build highly-distributed stateful applications which are very maintainable, like our community platform.